前提
MCP(Model Context Protocol,模型上下文协议) 是 AI 领域的一种开放标准,旨在为大型语言模型(LLM)与外部工具、数据源提供统一的交互方式,类似于“AI 世界的USB-C接口”。
MCP 能做什么?
- 标准化集成:让不同 AI 模型(如GPT、Claude)无缝连接数据库、API、文件系统等,无需为每个工具单独适配。
- 动态任务执行:支持多步复杂操作(如“查天气→存笔记”),比传统插件更灵活。
- 跨模型兼容:一次开发,多模型复用,降低开发成本。
- 实时上下文管理:AI 可记住前序交互,提升任务连贯性(如连续查询“附近咖啡馆→评分最高”)。
简言之,MCP 让 AI 不再“纸上谈兵”,而是真正帮你干活——从数据分析到自动化办公,都能更智能地完成。
为什么需要 MCP 桥接 GraphQL 与 LLM?
解决 LLM 的「动态数据困境」
- 静态知识局限:LLM 依赖训练时的静态数据,无法直接访问实时业务数据(如数据库、API 最新状态)。
- 上下文缺失:传统 Prompt 工程难以传递结构化数据(如用户画像、订单记录),导致回答泛化或错误。
- 权限与安全:直接暴露数据库或 API 给 LLM 有风险,需中间层控制访问边界。
MCP 的核心作用
- 协议化上下文注入:将 GraphQL 查询的实时数据按标准协议(MCP)格式化,作为「动态上下文」注入 LLM 推理过程。
- 解耦数据与模型:GraphQL 作为灵活的数据聚合层,MCP 作为适配层,避免硬编码数据逻辑到模型。
接入 GraphQL MCP 能力
社区很快就做了 GraphQL 的 MCP Server 实现,我们先不重复造轮子,取 mcp-graphql 为例子来一个快速原型。
https://github.com/blurrah/mcp-graphql
https://github.com/saewoohan/mcp-graphql-tools
构建一个 GraphQL Demo 服务
如果你已经有 GraphQL 服务了,可以忽略这一步
参考 Apollo Server 官网文档(https://www.apollographql.com/docs/apollo-server/getting-started),创建一个新项目:
- 创建一个空目录
graphql-server-demo - 执行
npm init --yes && npm pkg set type="module"初始化 package.json - 使用 npm 安装
@apollo/servergraphql - 在项目目录下创建
index.js-
index.js代码样例import { ApolloServer } from '@apollo/server'; import { startStandaloneServer } from '@apollo/server/standalone'; const typeDefs = `#graphql type Staff { english_name: String leader_name: String } type Query { staffs: [Staff] } type Mutation { sendNotice(english_name: String!, message: String!): Int } `; const staffs = [ { english_name: 'xiaohu', leader_name: 'siubeng', }, { english_name: 'faker', leader_name: 'siubeng', }, ]; const resolvers = { Query: { staffs: () => staffs, }, Mutation: { sendNotice: (_, { english_name, message }) => { console.log('sendNotice: english_name:', english_name, 'message:', message); return Math.ceil(Math.random() * 1000000000); }, }, }; const server = new ApolloServer({ typeDefs, resolvers, }); const { url } = await startStandaloneServer(server, { listen: { port: 4000 }, }); console.log(`🚀 Server ready at: ${url}`);
-
- 执行
node index.js运行 GraphQL Demo 服务,将会通过 4000 端口提供接口服务
可以通过 https://studio.apollographql.com/sandbox/explorer/ 调试你的本地服务,执行这样的查询 case:
query ExampleQuery {
staffs {
english_name
leader_name
}
}成功的话,就会得到这样的回应:

这个 Demo 提供了两个接口:查询员工信息 和 发送消息。文章后面会围绕着这两个操作和模型对话,你可以根据自己实际场景调整。
在 Cherry Studio 上配置 MCP 和模型服务
配置 MCP
个人常用的第三方本地客户端是 Cherry Studio,只讲讲在这个上面的配置方法,其它客户端大同小异。
点击 设置 - MCP 服务器,添加服务器
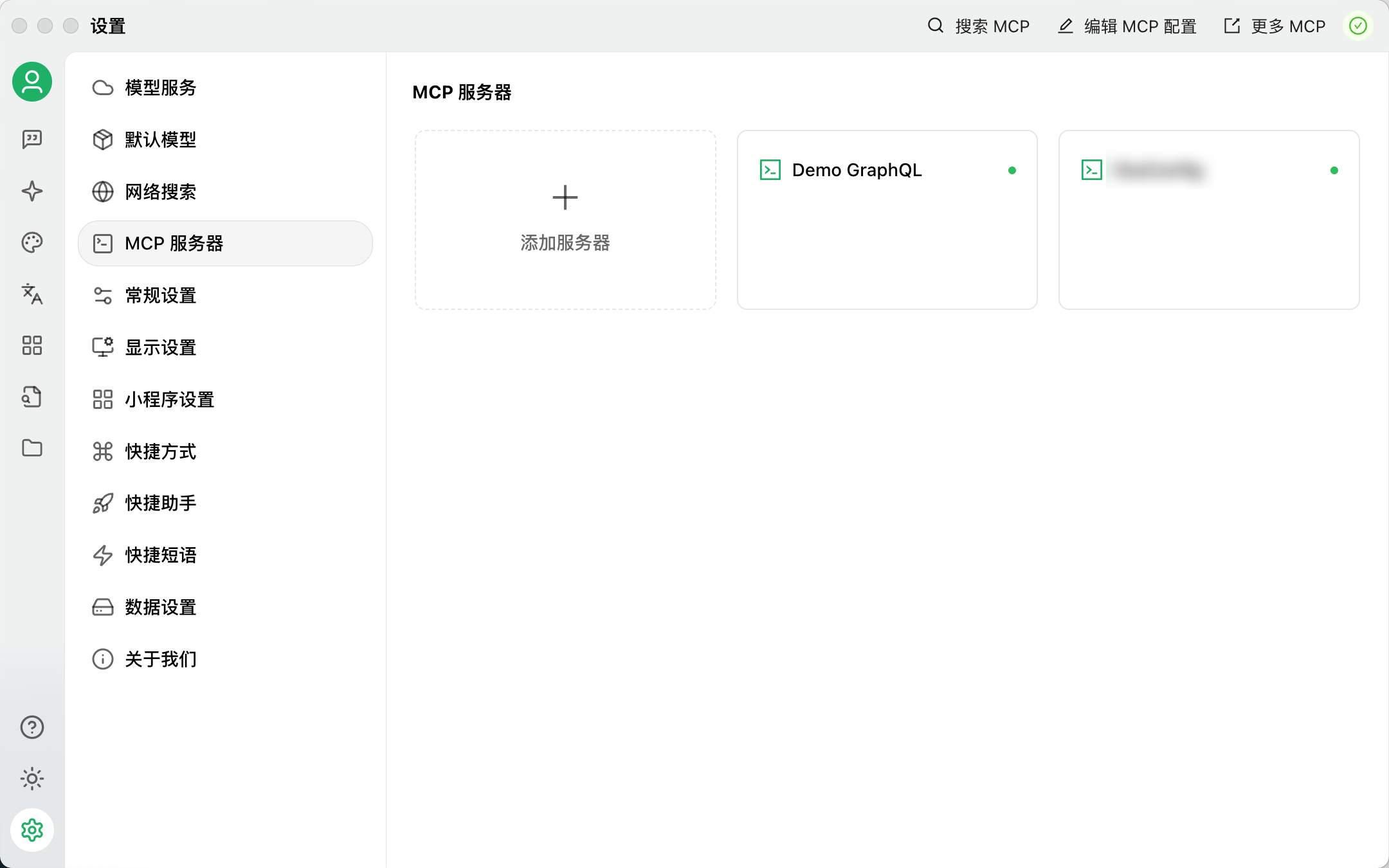
配置如图:
-
名称:自己填写
-
类型:标准输入/输出(stdio)
-
命令:
npx -
参数:
mcp-graphql -
环境变量(注意
ALLOW_MUTATIONS参数会允许调用 GraphQL Mutation 接口,小心对待):ENDPOINT=http://localhost:4000 ALLOW_MUTATIONS=true
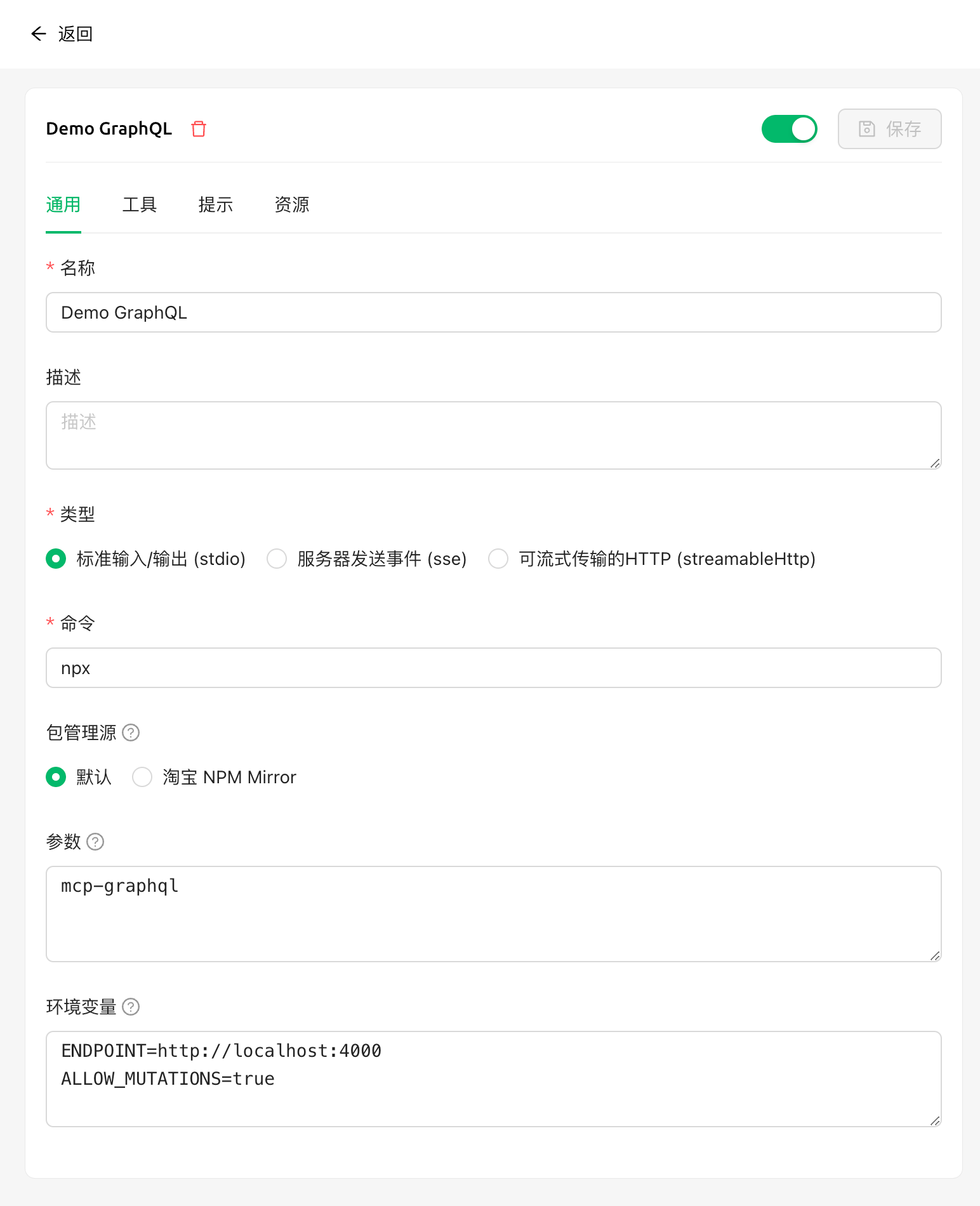
注意右上角的状态标志,可能会提示 UV/Bun 需要安装,否则没法跑起来 npx(即便你自己的环境已经有 Node.js 了)
创建智能体
-
提示词 Prompt 示例
你是一个 SQL/GraphQL 数据查询专家,可以根据用户输入的查询需求,利用 GraphQL MCP 查询相关数据,返回结果给用户。查询过程: 1. 先使用 introspect-schema 接口找到合适的接口 2. 构造接口查询语句,并传入参数 3. 通过 query-graphql 接口执行查询 选择接口需要注意: 1. 尽量使用版本最新的,不要使用 deprecated 的接口 2. 允许联合多个接口完成一次复杂的查询 3. 遵守接口请求参数规范 输出时需要注意: 1. 列表/表格数据使用 Markdown Table 格式 2. 接口默认限制最大返回值,按需支持分页
模型我选择了 deepseek-ai/DeepSeek-V3 ,你也可以接入 Claude、OpenAI GPT 等模型,注意小参数效果会很差,调用 MCP/Function Calling 需要对上下文的注意力表现比较好,能够稳定输出调用格式。
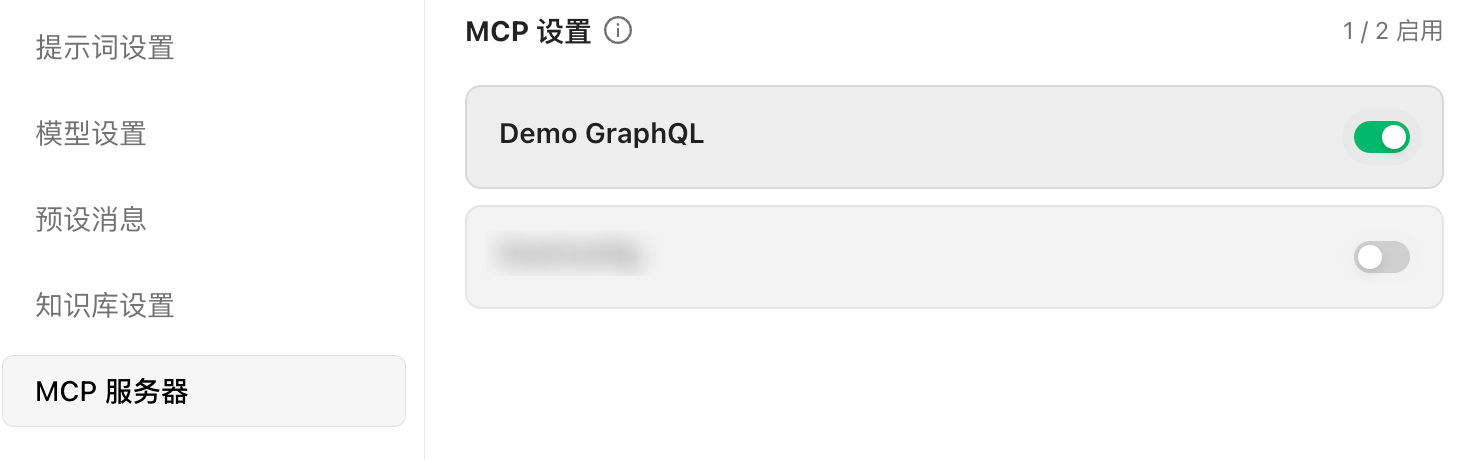
MCP 服务器中启用刚刚的配置:
试用一下
使用刚刚创建的智能体新建一个对话,根据我的 GraphQL Demo 能力范围,编写一条测试消息:
帮我通知 siubeng 的下属:早点下班得到的对话截图:

同时我在 sendNotice 接口的 Resolver 简单加了一个日志输出用来证明成功调用,也可以看到日志:

使用 Dify 构建 GraphQL 查询智能体
Cherry Studio 只适用于本地个人使用的场景,一些团队通过 Dify 平台搭建 LLM/智能体应用给团队成员使用,结合 GraphQL 可以构建一个简单的数据查询智能体。
下面以 Dify 官网的 Docker Compose 部署 为例子,讲解如何使用 Dify 构建 GraphQL 查询智能体。
顺着刚刚的思路,我们需要做几件事情:
- 部署 GraphQL 服务
- 选择合适的模型
- 部署 MCP 服务器
- 将 MCP 服务器接入到模型/智能体
前两点在上一节讲过大同小异,我直接从「部署 MCP 服务器」开始讲。
Dify 社区市场目前可以直接获取到的 MCP 协议插件为「MCP SSE」,上面接入 Cherry Studio 我直接用了 stdio 模式来接入 mcp-graphql 插件到大模型中,我们需要另外借助一个工具帮我们把仅提供 stdio 模式的插件转换成 SSE 协议,来接入 Dify 上的 MCP 插件。
期望的通讯架构关系是:
GraphQL 服务 ↔ mcp-graphql ↔ MCP 协议转换(supergateway)↔ Dify MCP SSE 插件 ↔ Dify
部署 MCP 服务器
转换协议选用了 supergateway 项目,官方提供了 Docker 镜像,可以快速地部署到 Docker/K8S 上。在启动 Dify 服务的 docker-compose.yml 文件中的 services 配置节下面加入一个新的服务(注意不要写重复了):
services:
mcp-graphql:
image: supercorp/supergateway:latest
restart: always
command: >
--stdio "ENDPOINT=http://127.0.0.1:4000 npx -y mcp-graphql"
--port 8001上面配置的参数说明是:
--stdio:执行指定命令并通过 stdio 和 MCP 协议通讯,这里就执行了和我们上面 Cherry Studio 配置一样的命令--port:supergateway 服务监听 8001 端口提供 MCP Server SSE 服务
将 MCP 服务器接入到模型/智能体
在 Dify 管理面板的工具 Tab 上安装「MCP SSE」插件,安装后需要配置授权,填写自己的配置:
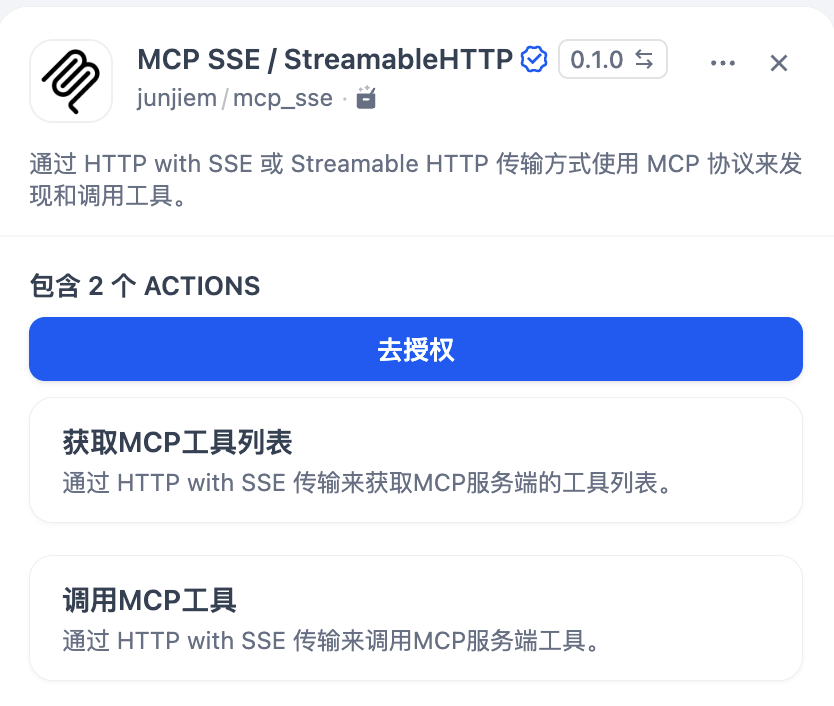
「MCP 服务配置」值主要需要修改第一个 Server 的 url 值(插件支持同时接入多个 MCP 服务器,本文不作详解,仅讨论只接入一个服务的情况),例如:
{"server_name": {"url": "http://mcp-graphql:8001/sse", "headers": {}, "timeout": 60, "sse_read_timeout": 300}}此处为 Docker Compose 默认网络策略中,同一个 Compose 的不同服务可以通过服务别名作为 Host 进行互相访问,因此我们填写了 http://mcp-graphql:8001/sse 这个值。
如果在 Dify API 容器访问不通 supergateway 提供的 MCP SSE 端口,请检查你的 Docker 容器网络策略,或者根据实际情况进行调整。
现在转到工作室 Tab,创建一个空白应用:
-
根据上一节教程填写提示词/Prompt
-
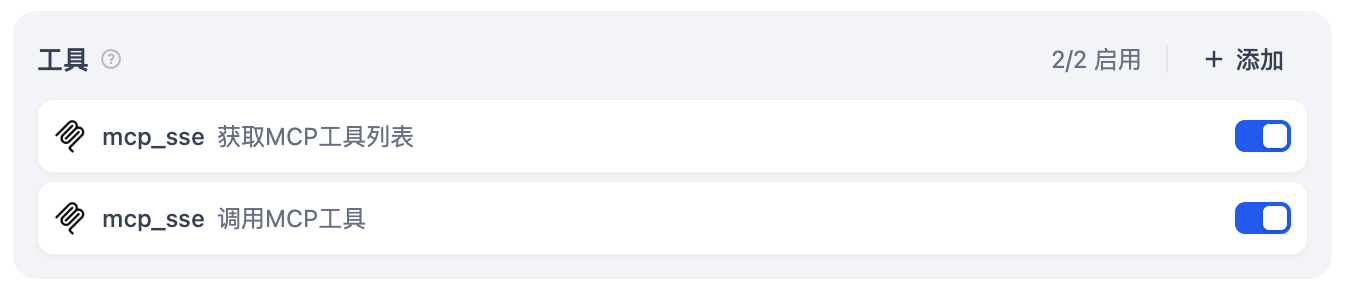
工具打开 mcp_sse 的两个函数
-
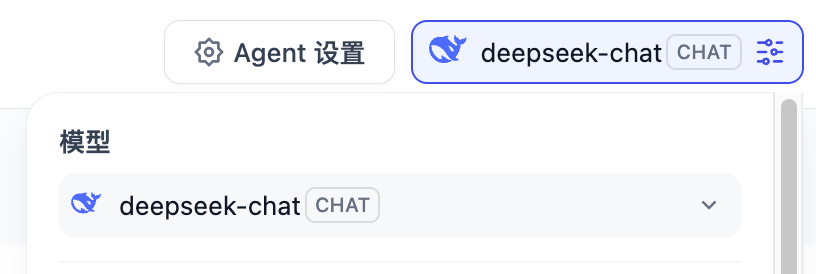
模型尽量选择对 Function Calling 比较好的,这里我用了 deepseek-chat
-
发布更新保存设置,在右侧就可以试验实际效果了
写到最后
文章开头说到我们通过 MCP 解决了 LLM 的「动态数据困境」,GraphQL 是我实战中接入的第一个数据源例子,实际上可能需要接入更常用的 SQL/KV(如 MySQL、Redis、PostgreSQL),又或是图数据库,甚至接入 gRPC/RESTful 服务。
不同的协议都需要各自开发 MCP Server,可能就会有人问现在通用智能体不是能自主学习,减少人工开发吗?不需要再去做 MCP 吧?
MCP 的核心理念是用结构化协议约束 LLM 的行为,在可控性和灵活性之间取得平衡,而通用智能体更偏向“全能但不可控”的通用性。同样的数据库查询任务,MCP 的接入让目标更加明确,在相对封闭领域的问题处理上效率更高,节省更多的推理成本。
这篇文章除了开头,都使用了落后的人类进行古法手写和实操,在互联网上留下自己作为人类的一些“噪音”,如有错误或建议欢迎交流~
PS: 这篇文章在 2025.04.22 已经完成初稿了,现在才发出来,拖延症严重~