背景
一次技术改造升级过程中,很多业务需要改造为经过基于 APISIX 实现的一个 API 网关, 部分业务改造前是 Apache2 + Python CGI 框架提供 HTTP 服务,且部分页面源码使用 GBK 编码, 中间不做特殊处理传回浏览器时,由浏览器自动识别内容编码解析。
问题定位
这一部分源码使用 GBK 编码的页面在迁移后,Chrome 浏览器访问出现乱码,经测试对比发现 Content-Type 头
在经过 API 网关代理后,被额外加上了 ;charset=utf-8,原文是只有 text/html,写一个简单的 HTTP CGI 验证得到相同的结果。
解决方式
经过问题定位,可以确定是 APISIX 这一层引发的问题,而 APISIX 主要由 NGINX + OpenResty + APISIX Lua 代码 组成,
我们先从 APISIX 源码入手发现可以 config.yaml 中配置:https://github.com/apache/apisix/blob/cf8429249e7e28fa1fcdcec5f4d4b7b8612f4ca3/conf/config-default.yaml#L247
在 yaml 配置中它位于 nginx 配置节,说明这个能力是复用了 NGINX 自带的 charset 模块(http://nginx.org/en/docs/http/ngx_http_charset_module.html#charset),
当 http 配置节中的 charset 值不为 off 时,就会在 Content-Type 头补充 charset=xxx,行为符合我们发现的问题表现。

我们尝试将 charset 改为 off,重启 APISIX 服务,重新请求有问题的 GBK 页面源码,问题解决!
前端展示原理
要了解 Content-Type 的编码设置有多重要,可以进一步研究浏览器行为和源码(以 Chrome 106 版本)发现:
当请求中 Content-Type 头指定了 charset 编码或 XML/HTML/CSS 内容中存在规范的编码(如 HTML5 <meta charset="UTF-8"> 标签),Chromium 系浏览器(Blink)会按优先级来决定如何解编码(从上至下,上为优先级最高):
-
HTTP 头
Content-Type中的charset部分 -
HTML
<Head>内<meta>标签中的charset属性值 -
文件头
<?xml>标签中的encoding属性值
也就是说,即使 HTML 文件自己声明了正确 charset 编码,如果服务端响应时设置了错误的 Content-Type,前后端同学就得排查一番了。大多数情况团队里的开发新人(包括我)肯定是希望能统一使用 UTF-8 编码,但有很多 GBK 编码的历史包袱,没有人强制推动去改,大家就尽量不想去碰了,搞清楚这里的编码处理规则,能节省不少时间。
当然还有一种情况,就是上述属性均未提供时,Blink 渲染引擎会进行检测:https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/renderer/platform/text/text_encoding_detector.cc;l=50;drc=27e39fa1dd71076618c358639ed8a327bc3873c4
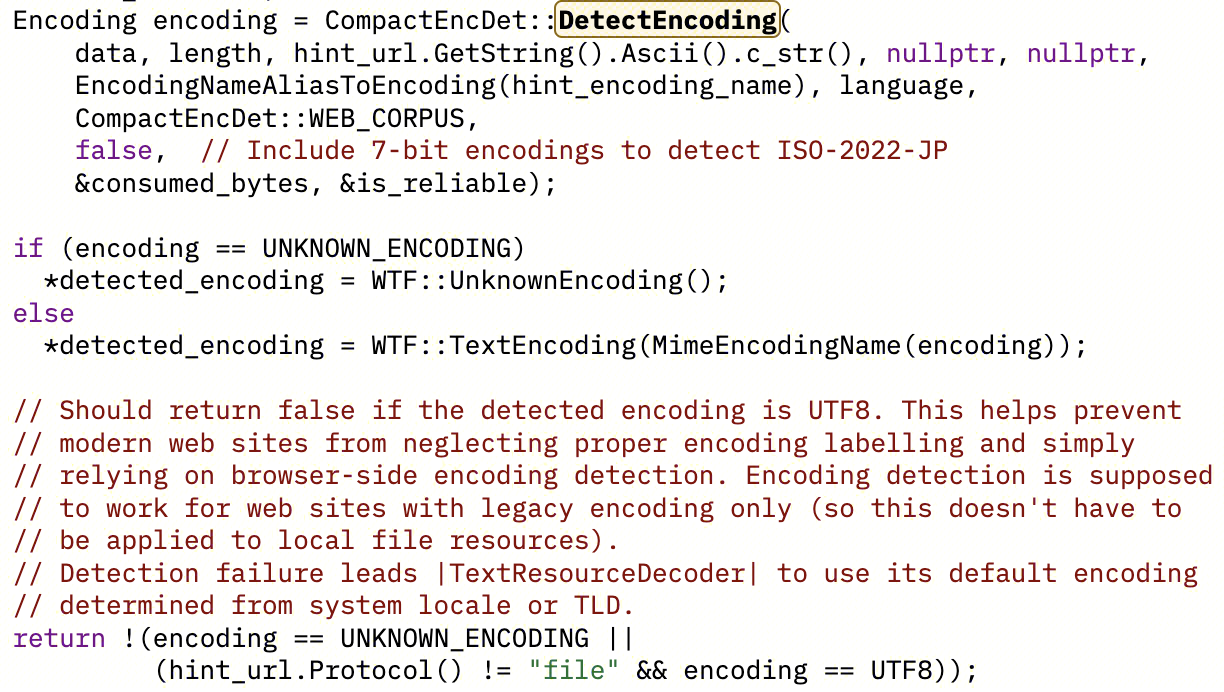
最终引用 Google 自己开源的 compact_enc_det 库(GitHub,可以单独在其他项目中使用),
调用 CompactEncDet::DetectEncoding 去检测内容计算最近似的编码方式:https://source.chromium.org/chromium/chromium/src/+/main:third_party/ced/src/compact_enc_det/compact_enc_det.cc;l=5537;drc=27e39fa1dd71076618c358639ed8a327bc3873c4